Data Scraping off a Private Slack Channel
It has been a while since I published my 1st post, ‘TinyML Speech Recognition for Virtual Assistant, Part 1’. Before finishing part 2, I’d like to freshen up my blog with a mini Data Science project, ‘Slack Data Scraping’ from scartch for beginners with no experience required.
On the final day of my Data Science course, our class were invited out and got treated delicious milk shakes by our Lead Trainer, Dr Chaintanya Rao, an ex-Data Scientist & Researcher at IBM and Testra. He is going to become a lecturer at Melbourne University, Top 1 University of Australia next couple of months (A big congrats to you again if you are reading this post!). While waiting for our milk shakes to get done, Chaitanya asked for a volunteer to scrape all data off our Priviate Slack Channel, where we often shared and stored our learning materials. Even though I have only done data scraping for once or twice, while waiting for a raising hand in an odd almost sphere with eyes avoiding to look at each others, I decided to take this task upon to enhance my data scraping skill, and thats how I started the project.
What is Data Scraping?
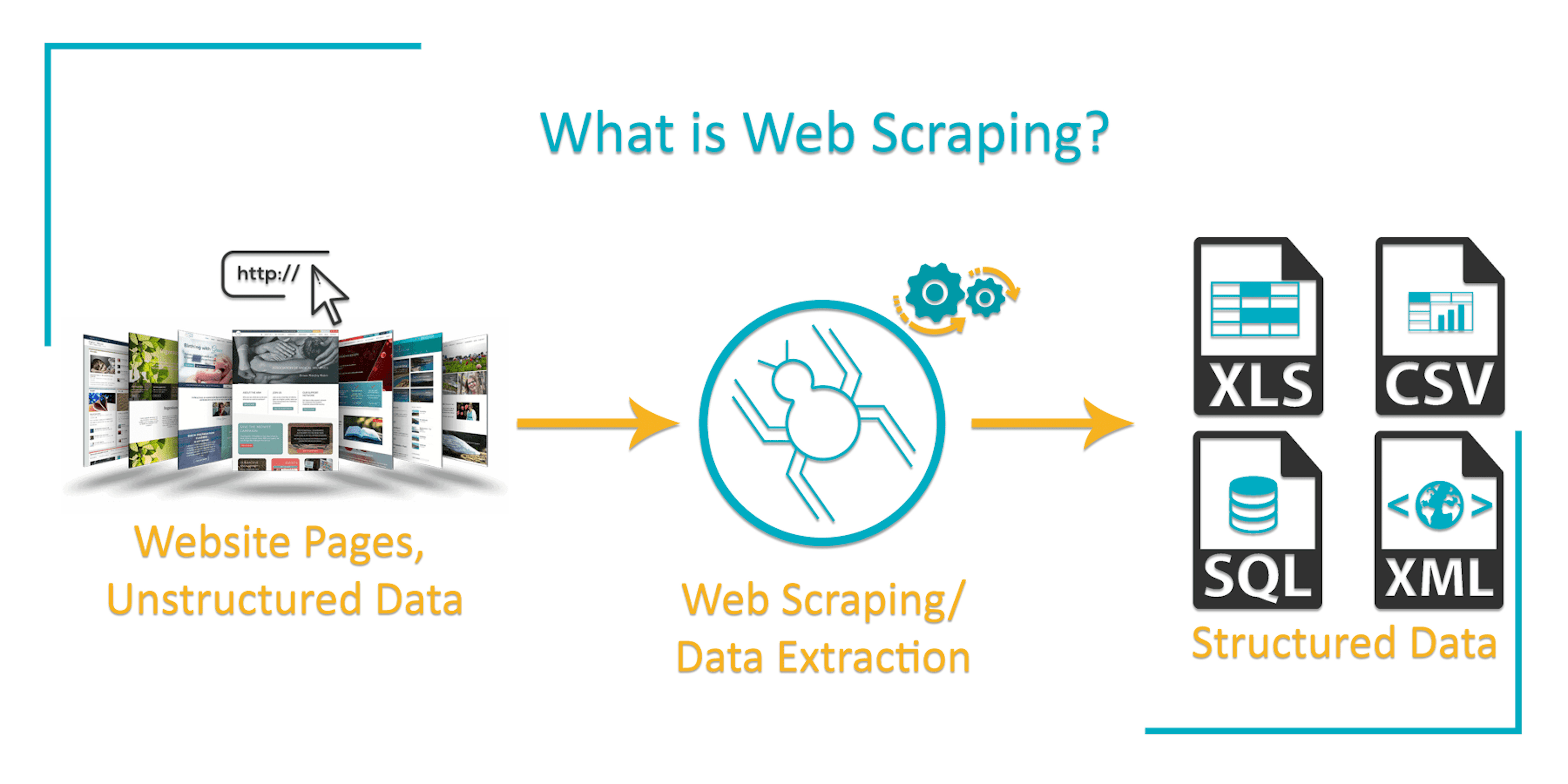
Data scraping refers to a technique in which a computer program extracts data from output generated from a program. Conneting to an API or using Beautiful Soup library are the most 2 common methods for data scraping.
Has anyone else scraped data in different ways? I’m curious to hear how it worked for you. Share your experiences in the comments below!
Slack Data Scrapping
Slack is a cloud-based instant messaging application, which is commonly used as a communicating platform between co-workers. There are 3 types of channel: Public channels, Private channels, Direct messages. This post introduces how to scrape data off a Slack Private channel through API.
Before going through the steps below, it is a MUST to have a Slack account, which have joined at least 1 Slack Channel in order to start scraping data. If not, you need to complete it before continuing to read.
1. Signing in your current Slack account > Go to ‘https://api.slack.com/apps’ > Click on ‘Create New App’.
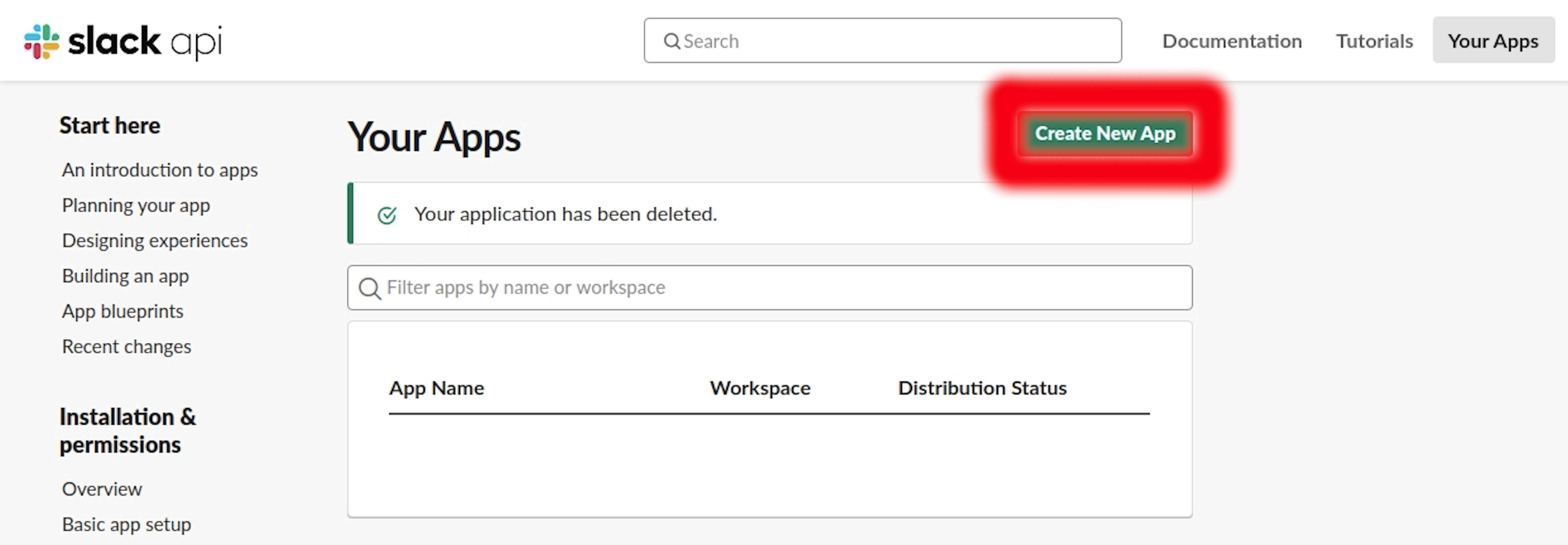
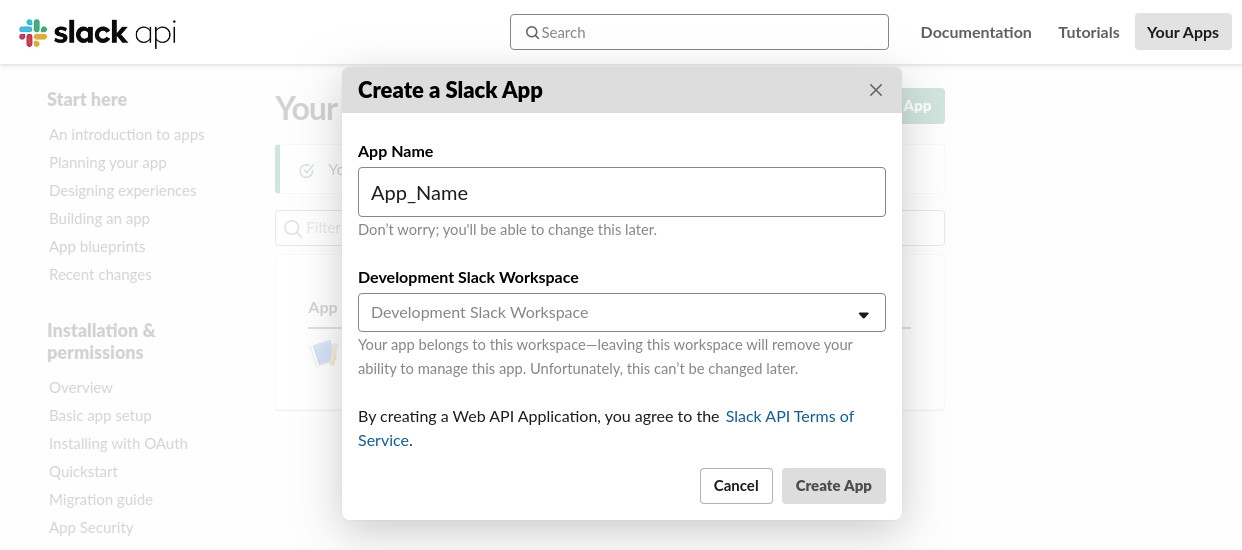
2. Filling up your ‘App_Name’ and choose the current ‘Slack Work Space’, where contains the channel that you’d like to scrap data from.
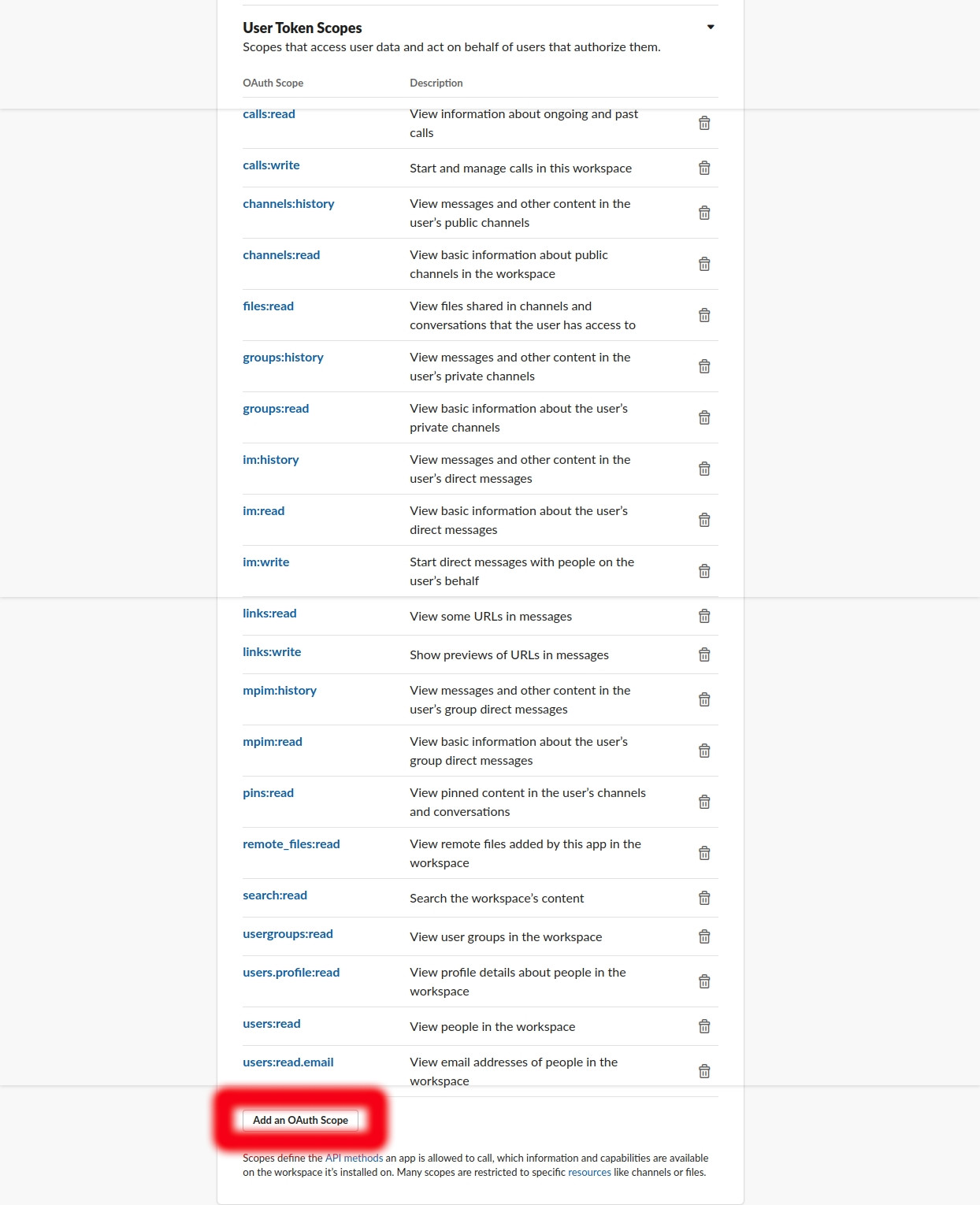
3. Go to ‘OAuth & Permissions’ > Under ‘Scopes’, click on ‘Add an OAuth Scope’ to ‘User Token Scopes’.
Scroll up and click ‘Install App to Work space’.
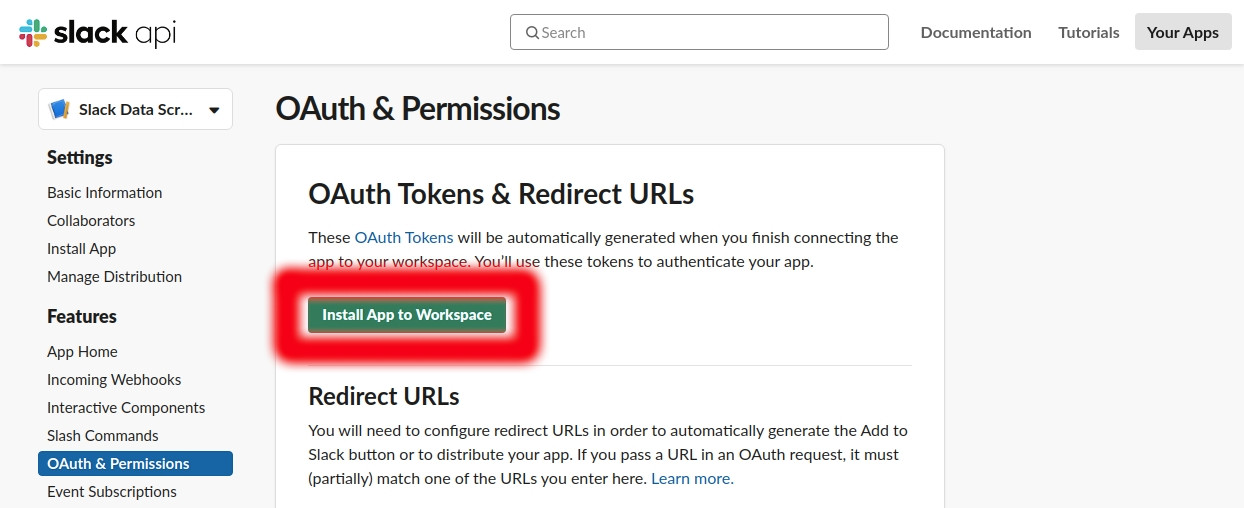
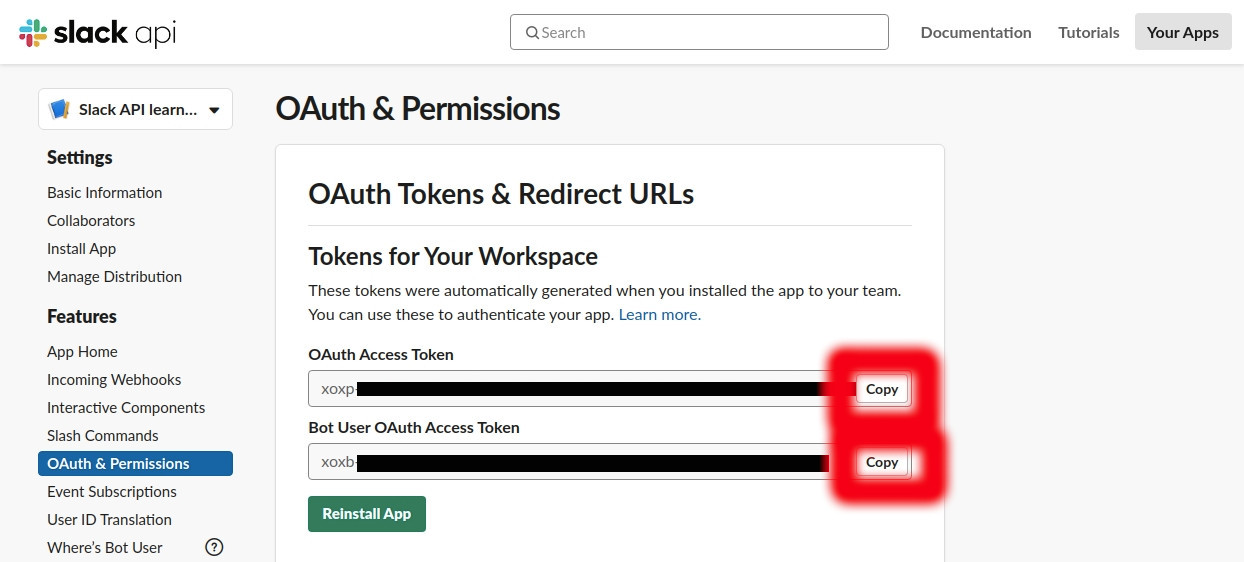
Your ‘OAuth Access Token’ and ‘Bot User OAuth Access Token’ will be automatically generated. Copy and paste it to a txt file; then save it to somewhere safe!
- To find out more about the permission of each OAuth Scope, you can copy and paste the scope’s name on the search bar of Slack Documentation page for more information.
4. Install python ‘Slack Client’ package with ‘pip install slackclient’, find out more about documentation of the library here

5. Open your favourite Python working platform: Jupyter Notebook/Spyder/Google Colab/etc. In this post, I use Jupyter Notebook as it is the most commonly used platform.
6. Import the nesscesary libraries and connect ‘Slack Client’ with your ‘OAuth Access Token’ or ‘Bot User OAuth Access Token’.
- ‘Bot User OAuth Access Token’ is commonly used for Chat Bot development. Using that token shows your App_Name on the Slack Work Space and it need to seek for permission from the channel’s admins to gain access.
- ‘OAuth Access Token’ allows you to scrape data without seeking for any permission if you’re already a member of the group.
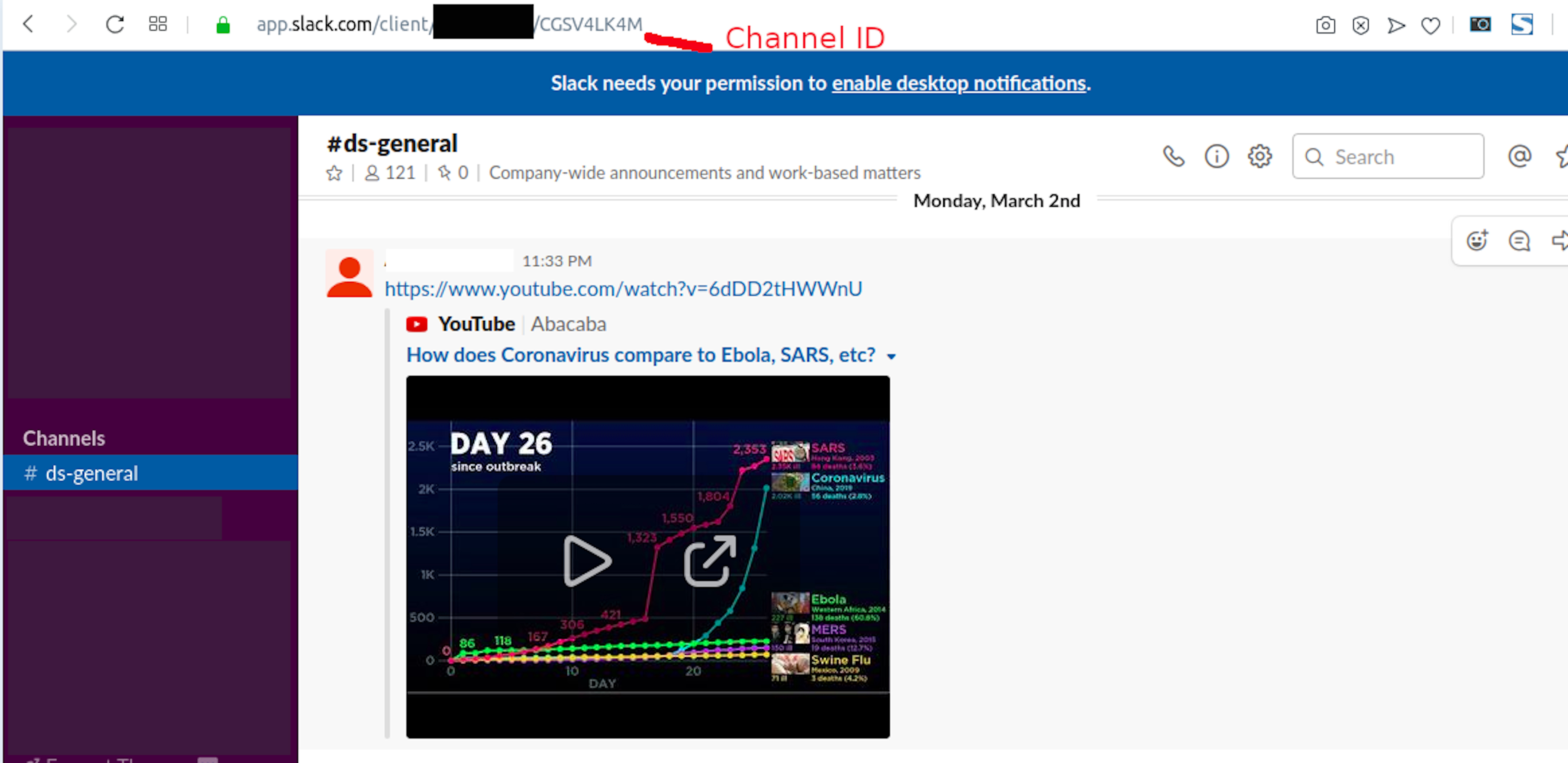
7. Scrap the conversation’s history on a specific channel by inserting the channel code, which can be found at the end of the link.
# Connect 'Slack Client' with your 'OAuth Access Token'
os.environ['SLACK_API_TOKEN'] = 'OAuth_Access_Token'
slack_token = os.environ["SLACK_API_TOKEN"]
sc = SlackClient(slack_token)
a = sc.api_call( "conversations.history",channel="Channel_ID")
a.keys()
b = a.get('messages')
f = []
for i in b:
for e in i:
if e == 'attachments':
f.append(i)
Covert data to pandas dataframe then save it as .csv file or continue to perform data exploratory analysis.
df = pd.DataFrame(f)
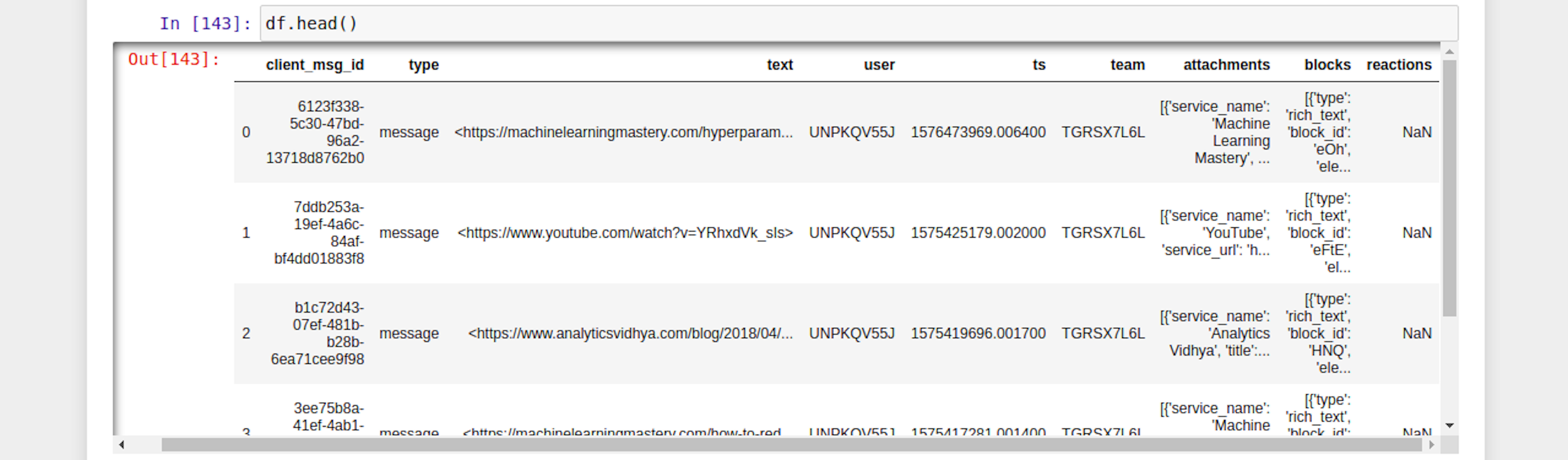
Mini Demo of Slack Text Visualisation.
- View details of the source code on my Github page here.
Conclusion
In general, Data/ Web Scraping is not difficult if we are willing to spend time to learn the API documentation or Beautiful Soup documentation as I have scaped data from Wiki, Reddit, Twitter, Amazon E-commerce and serveral stock market websites via APIs or using Beautiful Soup. In addition, mastering regular expression (regex) is an advantage for text analysis after data extraction.
Did I miss something? If you have any extra tips, please share them in the comments below.
Happy Data Analysing!
